Summary
One way to back up a website—whether your own or someone else's—is to use a tool that downloads the website. Then you can back up the resulting files to the cloud, optical media, etc. This page gives some information on downloading websites using tools like HTTrack and SiteSucker.
Note: Here's a list of the domains I have downloaded. Let me know if you don't want your site to be downloaded.
Contents
HTTrack
On Windows, HTTrack is commonly used to download websites, and it's free. Once you download a site, you can zip its folder and then back that up the way you would any of your other files.
I'm still a novice at HTTrack, but from my experience so far, I've found that it captures only ~90% of a website's individual pages on average. For some websites (like the one you're reading now), HTTrack seems to capture everything, but for other sites, it misses some pages. Maybe this is because of complications with redirects? I'm not sure. Still, ~90% backup is much better than 0%.
You can verify which pages got backed up by opening the domain's index.html file from HTTrack's download folder and browsing around using the files on your hard drive. It's best if you disconnect from the Internet when doing this because I found that if I was online when browsing around the downloaded file contents, some pages got loaded from the Internet, not from the local files that I was testing.
Pictures don't seem to load offline, but you can check that they're still being downloaded. For example, for WordPress site downloads, look at the \wp-content\uploads folder.
I won't explain the full how-to steps of using HTTrack, but below are two problems that I ran into.
Troubleshooting: gets too many pages
When I tried to use HTTrack to download a single website using the program's default settings (as of Nov. 2016), I downloaded the website but also got some other random files from other domains, presumably from links on the main domain. In some cases, the number of links that the program tried to download grew without limit, and I had to cancel. In order to download files only from the desired domain, I had to do the following.
Step 1: Specify the domain(s) to download (as I had already been doing).
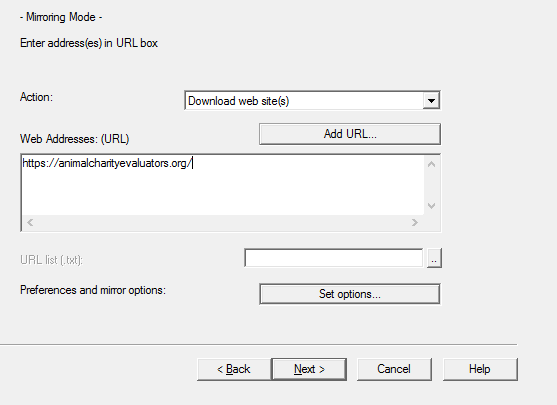
Step 2: Add a Scan Rules pattern like this: +https://*animalcharityevaluators.org/* . This way, only links on that domain will be downloaded.
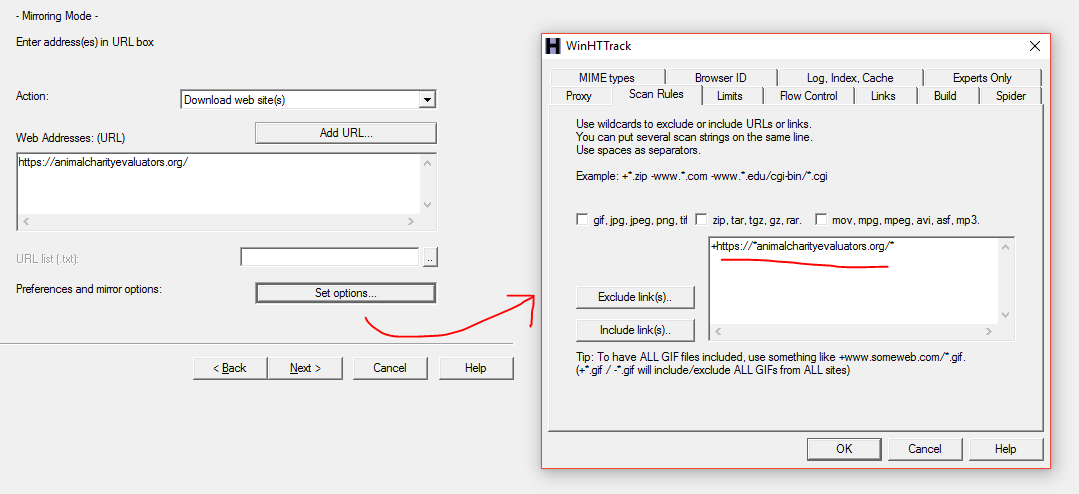
Including a * before the main domain name is useful in case the site has subdomains. For example, the site https://animalcharityevaluators.org/ has a subdomain http://researchfund.animalcharityevaluators.org/ , which would be missed if you only used the pattern +https://animalcharityevaluators.org/* .
Troubleshooting: Error: "Forbidden" (403)
Some pages gave me a "Forbidden" error, which prevented any content from being downloaded. I was able to fix this by clicking on "Set options...", choosing the "Browser ID" tab, and then changing "Browser 'Identity'" from the default of "Mozilla/4.5 (compatible: HTTrack 3.0x; Windows 98)" to "Java1.1.4". I chose the Java identity because it didn't contain the substring "HTTrack", which may have been the reason I was being blocked.
SiteSucker
On Mac, I download websites using SiteSucker. This page gives configuration details that I use when downloading certain sites.
Including redirects
I think website downloads using the above methods don't include the redirects that a site may be using. A redirect ensures that an old link doesn't break when you move a page to a new url. If you back up your website, it's nice to include the redirects in the backup, in case you need to regenerate your website in the future.
I'm not sure if there's a way to download the redirects of a site you don't own; let me know if there is. For a site you do own, sometimes you can back up the redirects by saving the relevant .htaccess file. In my case, I use the "Redirection" plugin in WordPress, and its menu has an "Import/Export" option; I find that the "Nginx rewrite rules" export format is concise and readable.
Non-linked content
HTTrack and SiteSucker are web crawlers, which means they identify pages on your site by following links. If you have content on your site that's not linked from the starting page you provide, then I assume these programs won't download it. (I've verified that this is true at least for SiteSucker.) If you want a page or file on your website to be downloaded, make sure there's at least one link to it. If you don't want the link to your content to be noticeable, you can add a hyperlink with no anchor text, like this: <a href="my_url.pdf"></a>
I use this trick for files that I store on my sites as backups. In particular, whenever I publish a substantive article on a website that I don't control, such as an interview published on someone else's site, I create a PDF backup of the page because I can't guarantee that the other person will keep the content online indefinitely. On my page I add a visible hyperlink that points to the other person's site, but I also upload the PDF backup to my own site in case the original content ever disappears. Since I want these PDF files to be included in backups of my website content, I create hyperlinks to these PDF files with no anchor text.
[Update in 2018: For content of mine that's published on other people's sites, I've decided to stop storing PDF backups on my website, since these backup files could theoretically still show up in Google results. Plus, if someone else takes his copy of the content down, there's a chance he did so deliberately, and I'd want to check with him before having a copy available on my site. My new approach is to back up my interviews and other content that's hosted on another person's site just to my private files—both a print-to-PDF copy and the raw HTML. If the content on the other person's site ever goes away, I can ask that person for permission to upload it to my own site.]
Images that are only used in the context of meta property="og:image" (for Facebook image previews) and that aren't actually linked from the body of your HTML also won't be captured by crawlers. Again, you can add an a href link to the image with no anchor text to make sure the image gets downloaded.
Images not on your site
If your site has images that aren't hosted on your own domain, then crawlers won't download those images when only downloading same-domain content. For example, if you use the WordPress Jetpack plugin with the Photon module, then an image that would normally be hosted at http://yoursitehere.com/wp-content/uploads/2014/04/myimage.jpg will instead be hosted at something like https://i0.wp.com/yoursitehere.com/wp-content/uploads/2014/04/myimage.jpg?w=642 . As a result, a crawler won't download this image.
At least in SiteSucker, I think you can work around this problem by downloading http://yoursitehere.com/wp-content/uploads/ in addition to http://yoursitehere.com . The download of http://yoursitehere.com/wp-content/uploads/ seems to pick up the images for some reason. (In fact, it picks up multiple sizes of each image.)
Saving PDFs of JavaScript calculations
A few of the pages on my websites contain JavaScript calculators, which produce output numbers, text, and graphs computed from inputs. For my calculators, the JavaScript is contained within the main HTML file, so backing up the HTML backs up the JavaScript. However, I think it's also important to save PDF backups of these pages that show the calculated results on the default input values, because JavaScript seems more brittle than plain HTML.
A regular HTML document is human-readable. Even if browsers 50 years into the future can't render present-day HTML files, a human with some knowledge of historical HTML tags could still understand 99%, if not 100%, of the HTML just by looking at it in a text editor. However, nontrivial JavaScript calculations are harder to understand just by looking at them. To get the results, you have to actually run the code, and it's not obvious to me that web browsers in, say, 20 years will be backward-compatible enough to run JavaScript that I might write today. Of course, I could probably update my JavaScript to accommodate future changes, but this requires constant vigilance, and there's a risk of introducing bugs along the way. Having a static snapshot of the results of the JavaScript calculations is useful in case the code breaks in the future and you don't have time to fix it. Plus, if you do update the code, once it's up and running again you can check the results of the calculations against the saved PDF files to ensure that you haven't inadvertently messed up the code while fixing it.
Compress archived websites?
Once you've downloaded a website using HTTrack or similar software, should you compress the website folder before backing it up to the cloud? I'm uncertain and would appreciate reader feedback, but here are some considerations.
My impression is that plain text files (such as raw HTML files) are more secure against format rot and bit rot, because "They avoid some of the problems encountered with other file formats, such as endianness, padding bytes, or differences in the number of bytes in a machine word. Further, when data corruption occurs in a text file, it is often easier to recover and continue processing the remaining contents." A Reddit comment says: "Straight up txt files have a very low structural scope / over head, so unless you're doing something funky, a bit error is limited to a character byte."
As a result, I plan to back up my own websites and other important sites mostly as uncompressed files (with some compressed copies thrown into the mix too). However, when backing up lots of other websites that are less essential, compression may make sense. This is especially so if the website download has a lot of redundancy. Following is an example.
Compression example with duplicate content
In 2017, I downloaded www.mattball.org using SiteSucker. The download had a huge amount of redundancy using the default SiteSucker download settings, because each blog comment on a blog post had its own url and thus downloaded the blog post again. For example, on a blog post with 7 comments, I got 8 copies of the blog HTML: 1 from the original post, and 7 from each of the 7 comment urls. The website download also included an enormous number of search pages. Probably I could prevent these copies from downloading with some jiggering of the settings, but I want to be able to download lots of sites with minimal per-site configuration, and I'm not sure that url-exclusion rules that I might apply in this case would work elsewhere.
In principle, compression can minimize the burden of duplicate content. Does it in practice? During the www.mattball.org download, I checked to see that the raw content downloaded so far occupied ~450 MB. Applying "Normal" zip compression using Keka software gave a zip archive of 88 MB, which is about 1/5 the uncompressed size. Not bad. However, a "Normal" 7z archive of the raw data was only 1.6 MB—a little more than 1/300th of the uncompressed size!
Using a simple test folder with two copies of a file, I verified that zip compression doesn't detect duplicate files, but 7z compression does. Presumably this explains the dramatic size reduction using 7z. This person found the same: "You might expect that ZIP is smart enough to figure out this is repeating data and use only one compression object inside the .zip, but this is not the case[....] Basically most such utilities behave similarly (tar.gz, tar.bz2, rar in solid mode) - only 7zip caught me [...]."
Security concerns?
Is it dangerous to download websites because you might make a request to a dangerous url? I'm still exploring this topic and would like advice.
My tentative guess is that the risk is low if you only download web pages from a given (trustworthy) domain. If you also download pages on other domains that are linked from the first domain, perhaps there's more risk?
HTTrack's FAQ says: "You may encounter websites which were corrupted by viruses, and downloading data on these websites might be dangerous if you execute downloaded executables, or if embedded pages contain infected material (as dangerous as if using a regular Browser). Always ensure that websites you are crawling are safe."
This page says: "SiteSucker totally ignores JavaScript. Any link specified within JavaScript will not be seen by SiteSucker and will not be downloaded." Does this help with security? How much?
GBC (2013): "Essentially all BROWSER vulnerabilities (ie. not vulns. in plugins like java or flash) involve and rely on JavaScript (JS) running."
Using downloads for monitoring website changes
Suppose you want to monitor what changes are done to your website over time, such as to track what revisions your fellow authors are making to articles. While I imagine there are various ways to do this, one relatively low-tech method is as follows. Periodically (say, every few months, or at whatever frequency suits you) download a new copy of your website using HTTrack or SiteSucker. Store at least the previous download as well. Then run diff -r on your two website-download folders to see what has changed. You could make this more sophisticated by adding logic to ignore trivial changes or changes in files you don't care about.
Of course, you could also do a diff on the website database .sql file directly if you can download it.